When your website optimizes itself every morning

I spent a week building an autonomous SEO agent for my own consulting landing page. This morning at 06:00 UTC it ran on its own for the first time — and caught a bug I had missed.
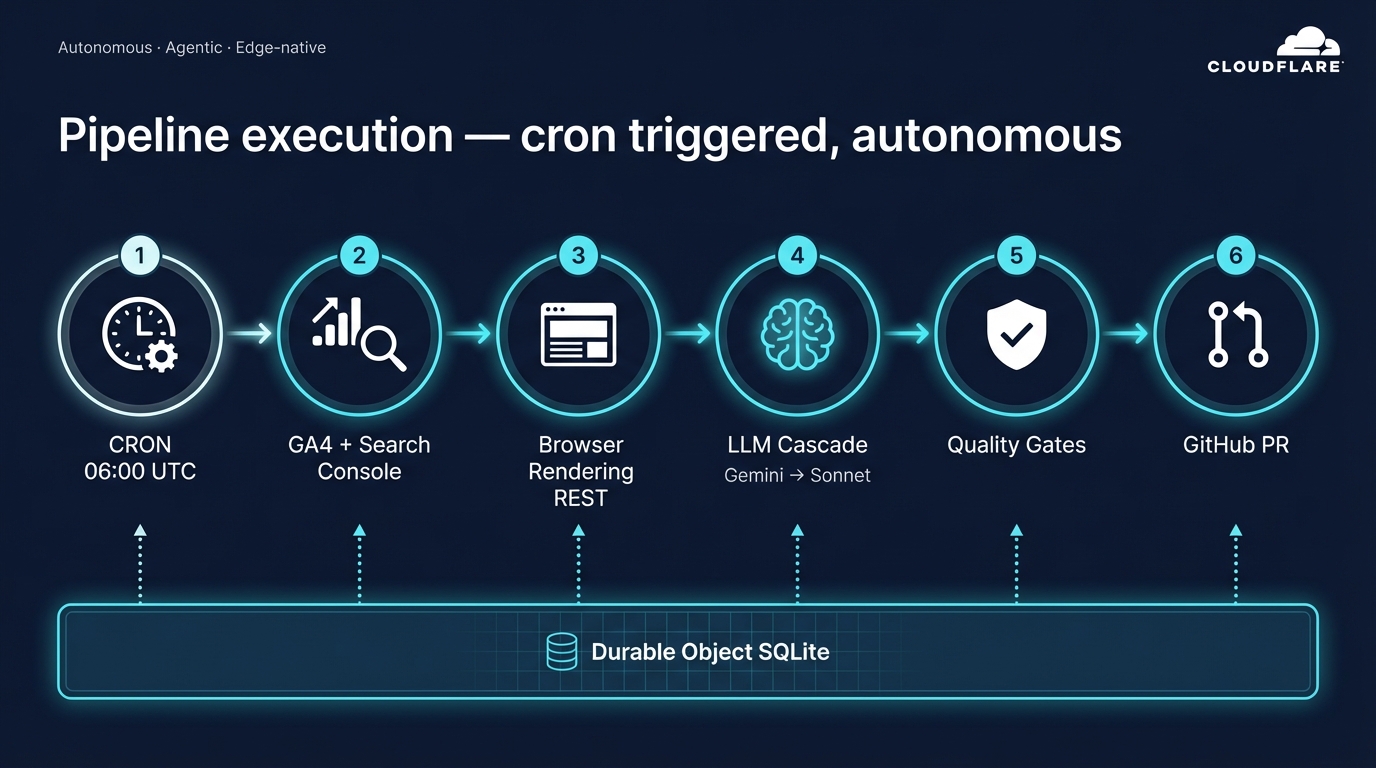
How the pipeline runs, every 24 hours
Every day at 06:00 UTC a Cloudflare Worker wakes up. It pulls the last week of GA4 sessions for the landing page, the last week of Search Console queries, a fresh capture of the live HTML, a Lighthouse audit (performance, accessibility, best practices, SEO, Core Web Vitals) from the PageSpeed Insights API, and a probe of whether GPTBot, ClaudeBot, and PerplexityBot can even reach the page. That's the raw input — four datasets, assembled without a human in the loop.
Then it thinks in two phases. Phase 1 reads the data and derives the site's context — who the target audience is, what language the copy is actually in, where the site sits competitively, whether there's a mismatch between what the page is optimized for and what visitors are actually searching for. Nothing is hardcoded. Phase 2 takes those derivations and proposes concrete changes — h1, title, meta description, structured data, CTA copy, performance fixes — each one citing the specific metric or HTML snippet that justified it.
The proposals land in a pull request on the site's repo. A human reads the diff, approves or rejects, and the auto-deploy cron ships whatever gets merged. No autonomous writes to production, ever.
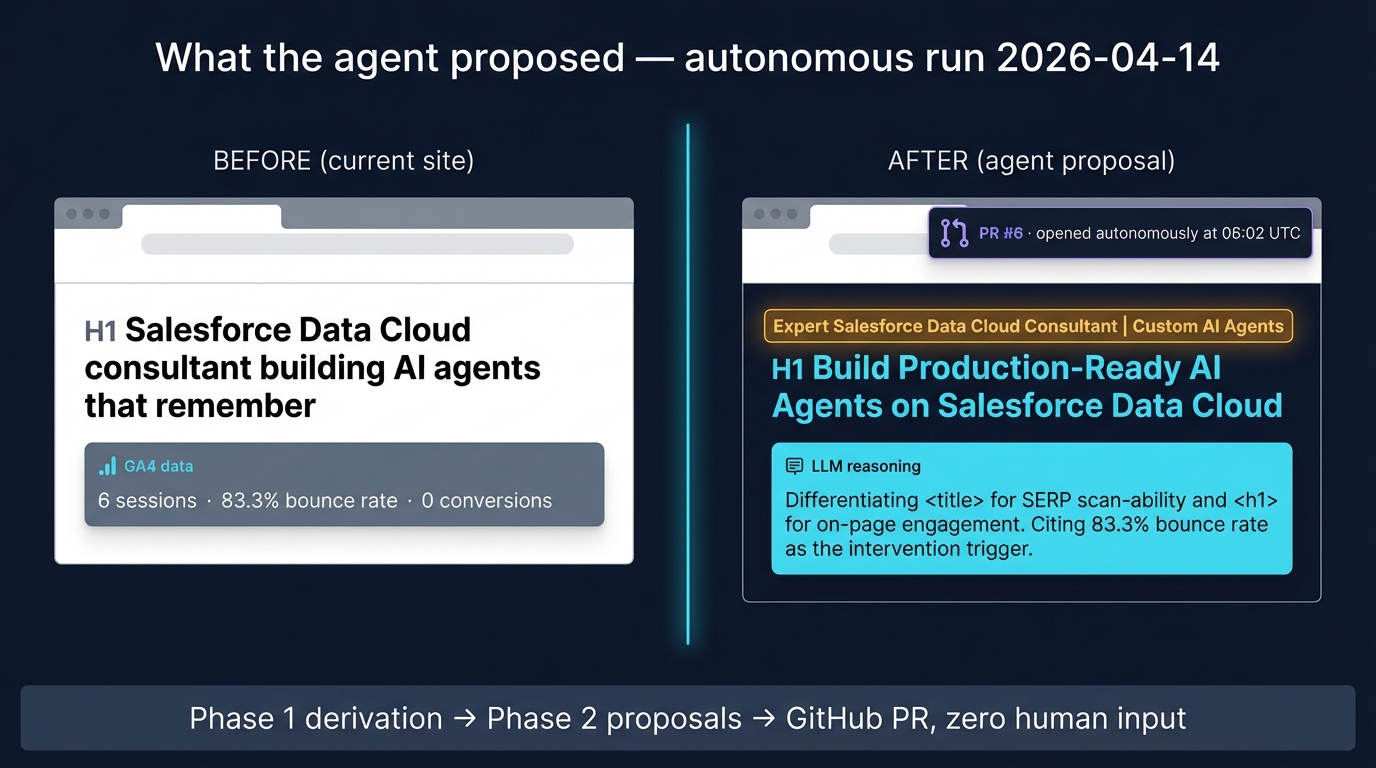
What it found on day one
This morning's first fully autonomous run correctly figured out three things about my site from the data alone. It wasn't told. It derived.
One: the site is selling to US and EU enterprise buyers (from the Search Console query language, the GA4 country mix, and the JSON-LD Service descriptions). Two: it's in a cold-start position — no organic presence yet, no top-5 keywords to protect. Three: there's a Spanish phrase embedded inside the JSON-LD alumniOf block, a leftover from an earlier version of the site, that was confusing crawlers trying to classify the page as English.
I had reviewed this page by hand. Multiple times. I never caught it.
Here's the thing I keep thinking about. I built the agent to never assume. The whole reason Phase 1 derives context from data — instead of me hardcoding language=en into a config — is that I wanted the same pipeline to run against any customer site without code changes. That design choice is exactly what let it correct me. If I had hardcoded the language, it would have breezed right past the Spanish string as an outlier.
What's under the hood, in plain English
Why this matters beyond SEO
A few people in the agent space have been converging on a word for what this pattern is: entangled software. The idea, borrowed from physics, is that the product and the customer reshape each other. The customer's behavior shapes the software; the software shapes how the customer works; over time they become inseparable. It's the opposite of how software has worked for thirty years, when we built tools and asked humans to adapt to them.
This pipeline is a small, concrete proof of the concept for my own site. The agent reads my specific GA4 metrics, my specific Search Console queries, my specific HTML, my specific Lighthouse scores. It reshapes its proposals around what's actually on my page. If I point it at a different customer tomorrow, it will reshape around their data instead. The strategist prompt has no hardcoded language, no hardcoded audience, no hardcoded positioning — because those are the exact things that have to adapt.
What I find interesting is that "adaptive" isn't a marketing line here. It's a structural property of how the prompt was written. It has to derive, because it was never told. And because it has to derive, it ends up looking where the humans have stopped looking.
What's next
Right now the agent opens a PR with a JSON artifact describing what it wants to change. A human still has to translate that into real HTML and JSX edits. The next iteration of the pipeline closes that gap — it will patch the actual source files directly, run the build, and open a PR that a human can merge in one click. After that, the thing to watch is whether the Lighthouse feedback loop tightens over weeks: each run sees the previous run's outcomes, and the strategist can start prioritizing changes that actually moved the needle on real users, not the ones that just looked good on paper.
I'll keep publishing what happens as it happens. This is the first entry in what I'm calling Experiments — a running log of the pipeline's autonomous decisions, the bugs they catch, the ones they miss, and what I learn when the agent surprises me.